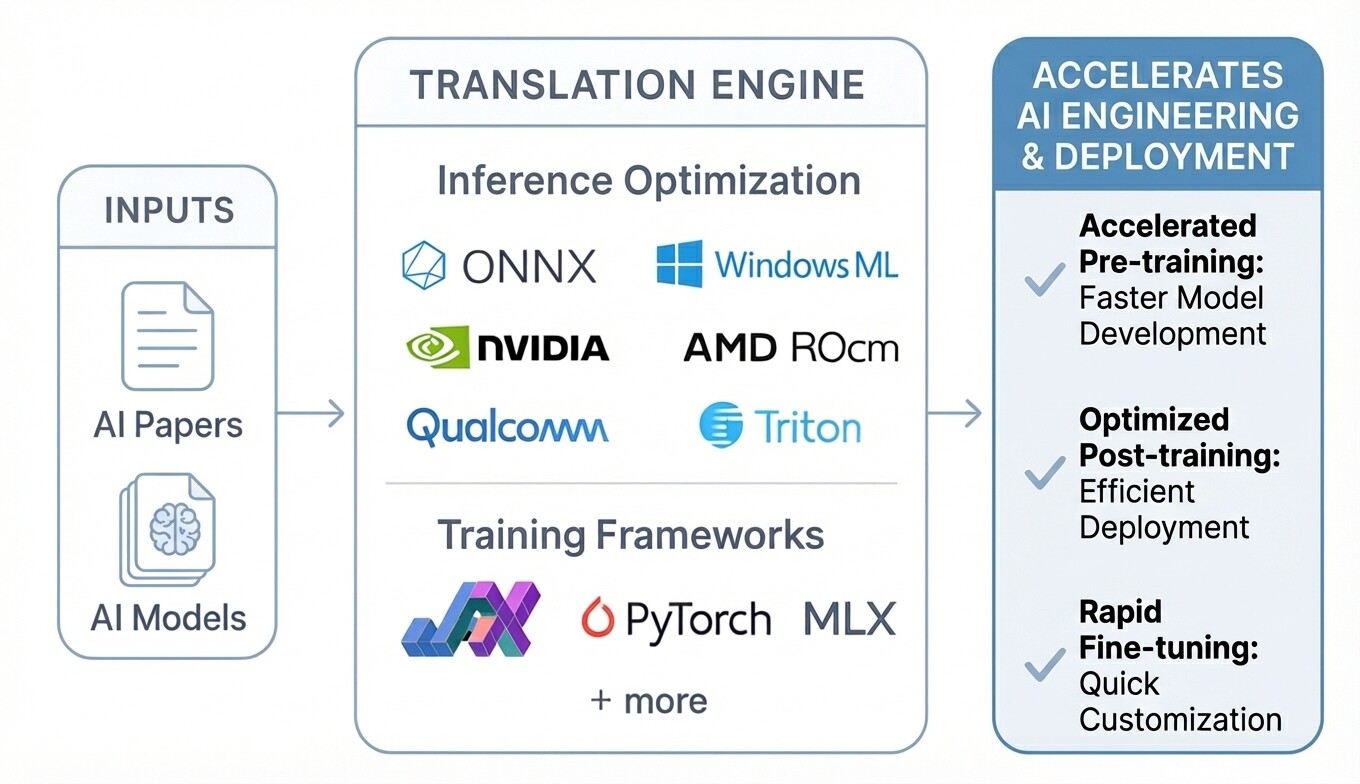
Universal Model Translation
From research to production. From any framework to any platform.
The Challenge
AI research moves fast, but production systems don't. Example: the best model for your use case is in JAX, but your infrastructure is PyTorch. The target is Apple Silicon, but the model was built for CUDA.
The Solution
I translate AI models across frameworks and adapt them to your target hardware. Shorten the path from research to production across platforms.
From the Blog
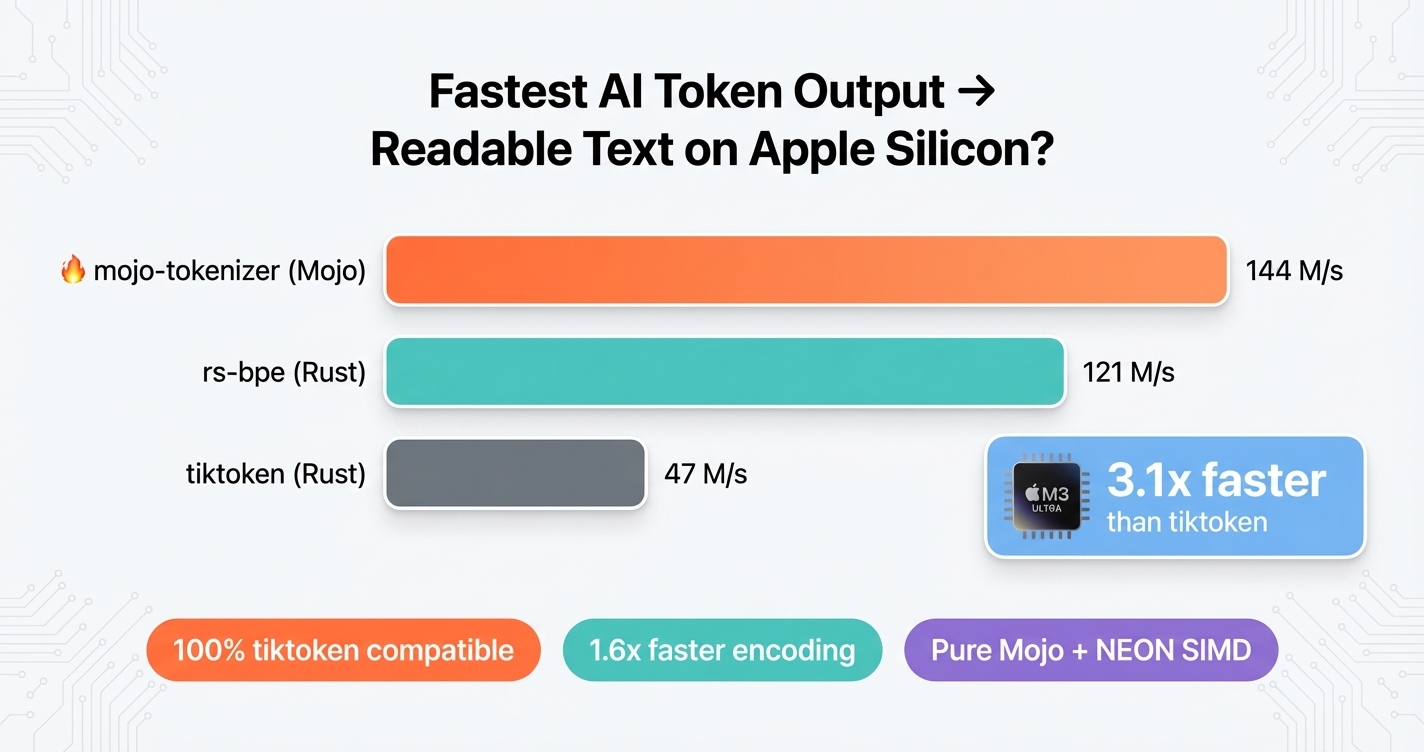
Mojo-tokenizer: Fastest AI Token Output → Readable Text on Apple Silicon?
mojo-tokenizer converts AI output to readable text at 144 million tokens per second — 3.1x faster than the industry standard. 100% compatible, rigorously benchmarked.
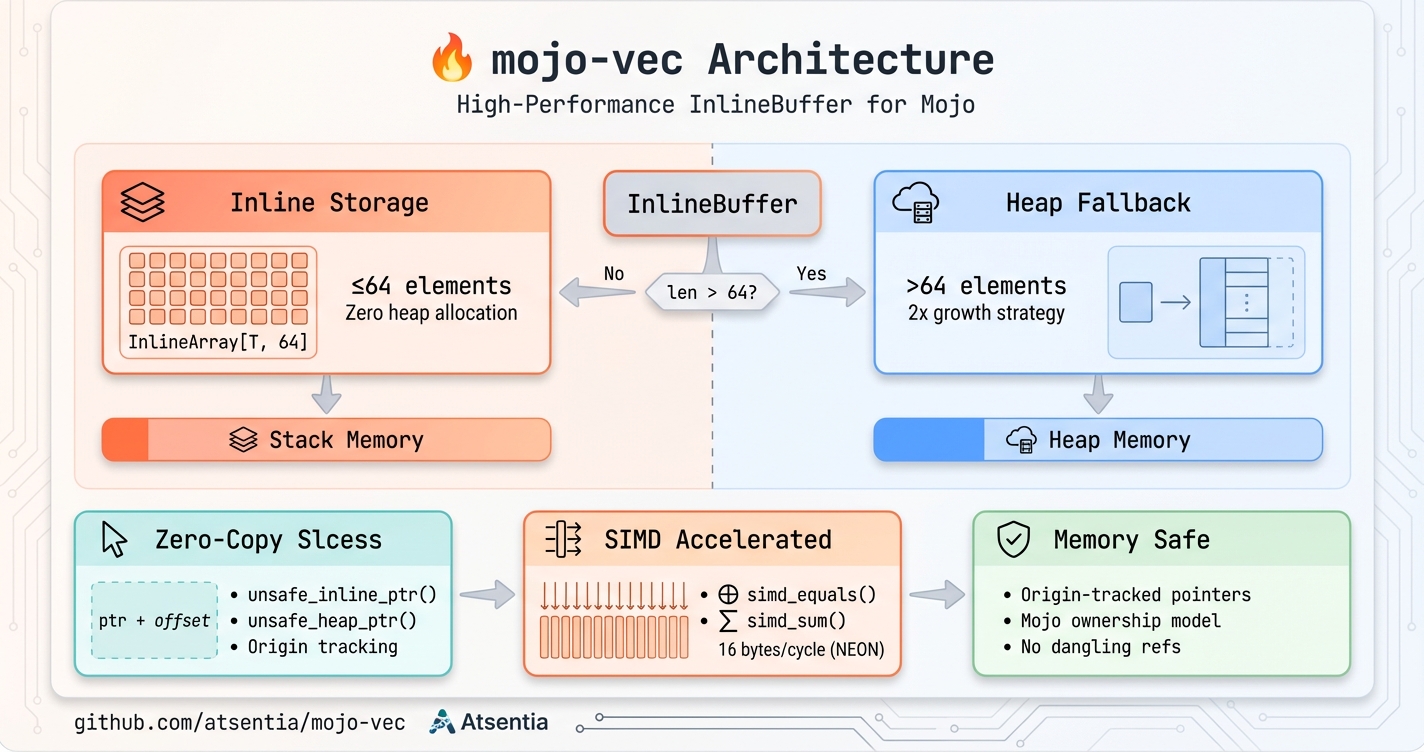
mojo-vec: Zero-Copy Buffers That Match Rust Performance
InlineBuffer stores small data on the stack, provides zero-copy slice access via pointer arithmetic, and includes SIMD-accelerated operations. The missing piece for high-performance Mojo.
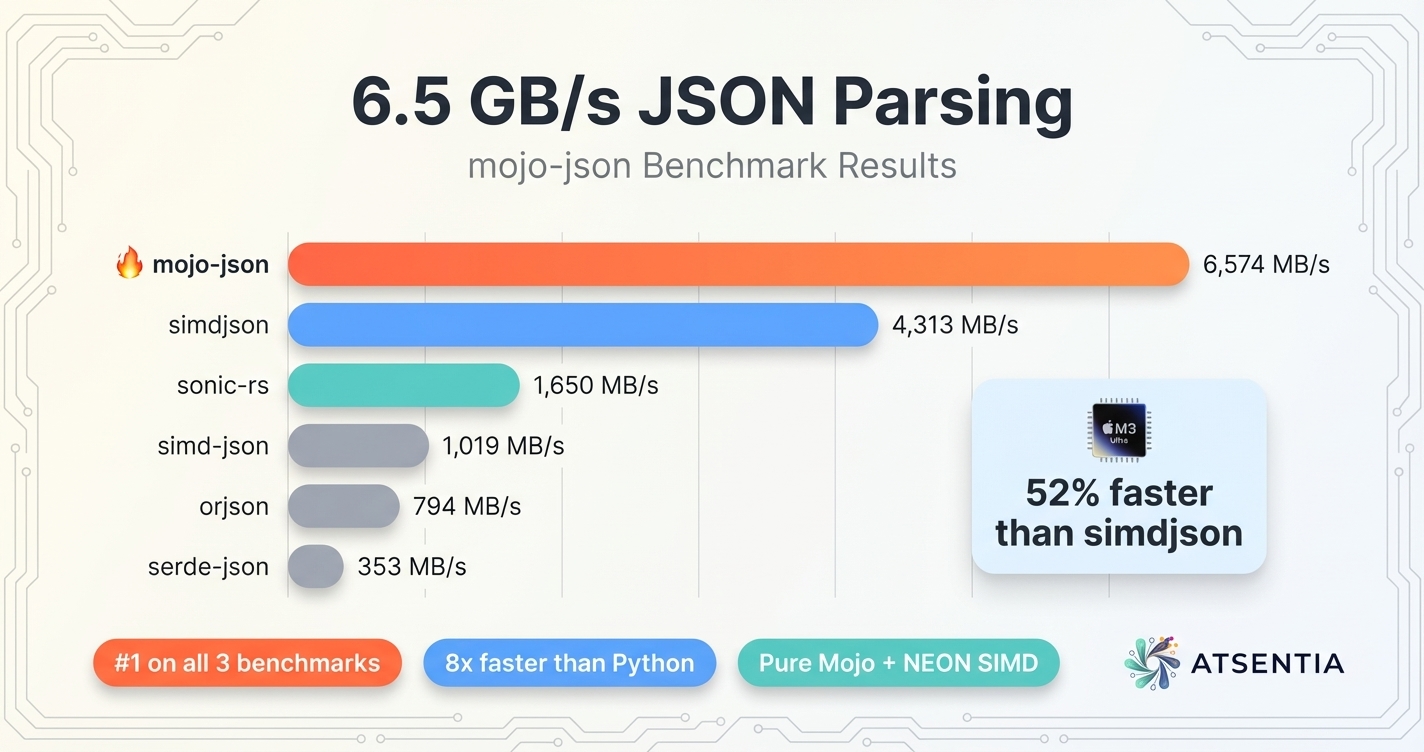
6.5 GB/s JSON Parsing in Mojo — Beating Rust and C++ on Apple Silicon
mojo-json achieves 6.5 GB/s throughput, outperforming the fastest Rust and C++ parsers by 52% on standard benchmarks. Empirical results from Apple M3 Ultra.
Ready to Get Started?
Send a short email with your AI challenge and we'll take it from there.
Start a Conversation