4 bits is all you need (and 3.6 bit you have?) for resource-efficient LLMs?
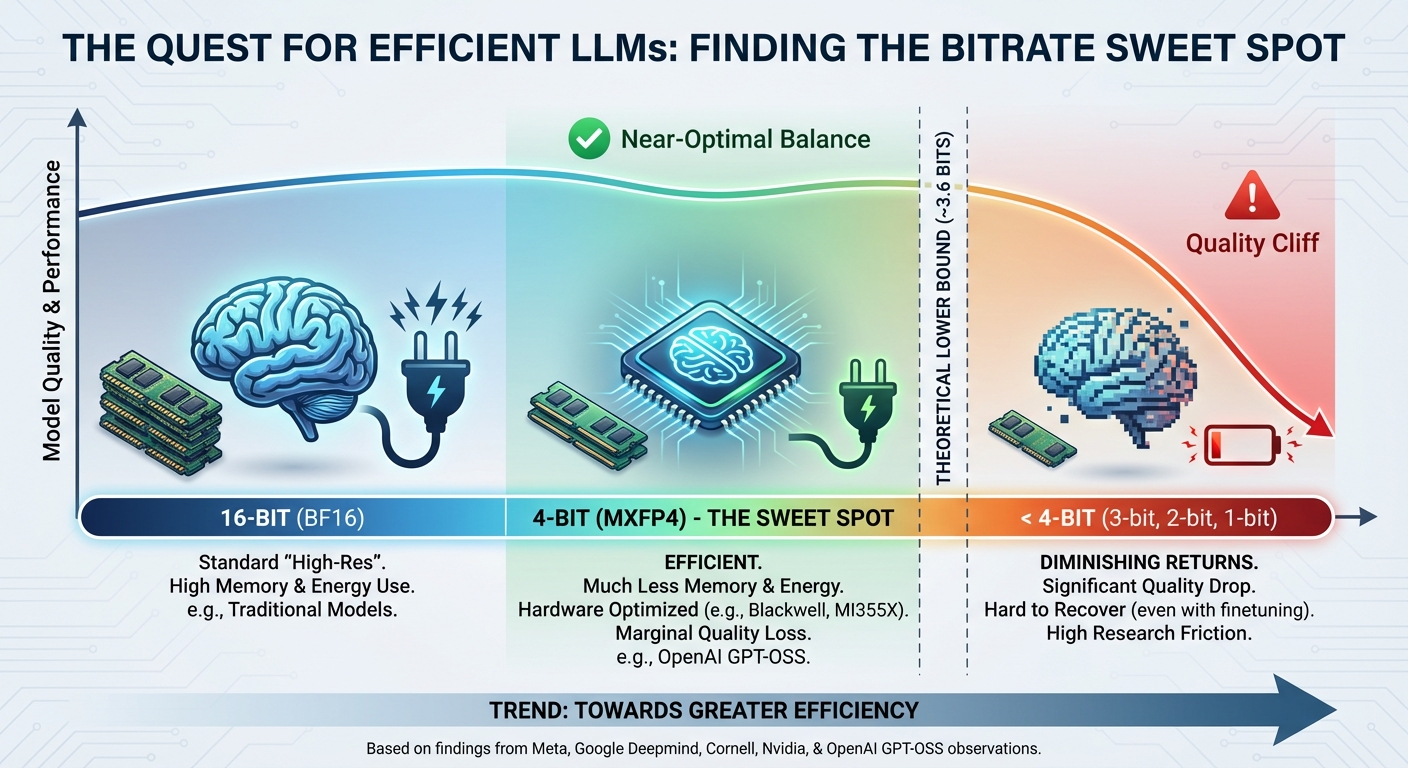
A few months ago OpenAI published their open weights model(s) GPT-OSS (20B and 120B), and one of the eye-catching characteristics was that it was heavily quantized - in other words “shrunk” or compressed - to 4 bits per parameter (MXFP4) instead of the commonly used 16 bit (BF16).
4 bit (“half byte”) means that the model uses much less memory, energy and also can run efficiently on hardware natively supporting 4 bit MXFP inference (e.g. Nvidia Blackwell B200/300 and AMD MI355X). With 4 bit compared to 16 bit there is some quality loss, but typically marginally.
But can we go even lower and represent the model in fewer bits per parameter, e.g. 3 bit, 2 bit or even 1 bit? There is highly interesting and seemingly promising research on more efficient quantization (few bit representation) of deep neural networks, however perhaps 4 bit is very close to the lower plateau - based on:
a) findings in an article with large empirical studies by Meta, Google DeepMind, Cornell University and Nvidia that language models have a capacity of 3.6 bits per parameter - Language Models Don’t Store Facts: They Compress Patterns - so perhaps 3.6 bit is a lower bound per parameter for efficient representation of deep neural networks?
b) and to a lesser degree personal testing on doing further quantizations on GPT-OSS 20B, it seems like when going to 2 and 3 bit even with (LoRA-based) finetuning it is hard to lift it back to close to 4 bit.
Related Reads
- OpenAI GPT-OSS Announcement
- Training LLMs with MXFP4 - Amazon and Cornell training models directly in 4 bit
- Pretraining Large Language Models with NVFP4 - Nvidia training directly in 4 bit
- Microscaling Data Formats for Deep Learning - Microsoft creating the MX data formats including MXFP4 and MXFP8